Take control of your data with DataValve
DataValve Project

License : GPL
Download Now
Introduction To DataValve
Developers can access a range of different data sources using the DataValve API making your code more reusable across different data providers and applications. The DataValve API is implemented by different data providers to create a single API through which you can access a variety of data sources. You can even write your own data providers with just two methods to let your DataValve aware clients access your own custom data stores just as you would a typical database data store.
One benefit of coding to the API is that the data provider implementation can be changed at a later date without having to change the client code. While most projects don’t swap out data providers, there may be a need to use additional data sources or access mechanisms, for example, returning objects from a native JDBC query instead of JPA, or ordering and paginating a cached in-memory set of objects, or accessing and paginating data from a CSV, XML or custom data stores as objects. DataValve also provides components for browsing huge virtual datasets in Swing.
Existing client code can be re-used against different data providers because they use the same interface mechanism to fetch the data. For example, a JSF paginator component that works with a JPA based provider will also work with a CSV file based provider. Our CSV dataset works with the JSF pagiantor, but we can take the provider and re-use it in a Swing or Wicket application.
Without DataValve, each data access and pagination component needs to be developed individually for each data access and view framework combination.
Applications Without DataValve
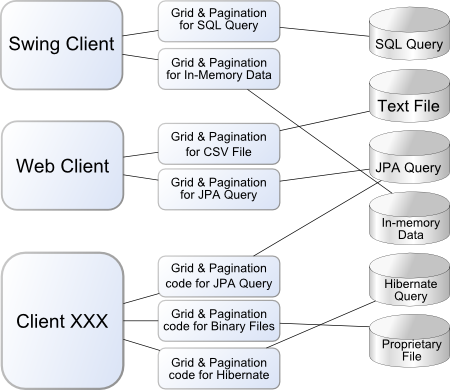
When you use DataValve to facilitate data access and pagination, you can take advantage of the API interface in your view code so you only ever need to implement the view code once and it can be re-used for each kind of data store. DataValve includes visual components for many visual frameworks such as Swing, JSF and Wicket so in many cases, you don’t even need to implement your own. If you want to do something very customized the DataValve API makes this easy.
Applications With DataValve
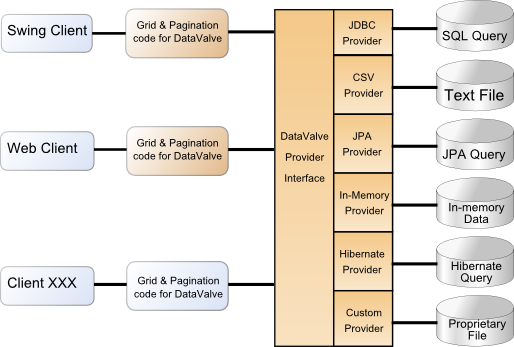
Here you can see that a visual framework is able to interface with each type of data provider via the DataValve API and that each type of data provider can be consumed by different front end clients. In essence, you can take any client components and it will can be used with any of the data providers.
- Download Now
- Install DataValve into Maven
- Read more about DataValve
- Documentation