Introducing DataValve
DataValve is a free open source library that facilitates the creation of re-usable view and data access components as well as providing a number of features for pagination, sorting and parameterizing queries. This article defines the problems DataValve aims to solve and how it solves them.
The need for DataValve
Most data driven applications have a need for displaying data that is organized into pages. Whether it is search results or sales reports, dumping a complete set of data results into a web page or a Swing grid is sooner or later going to run into problems as the datasets grow larger.
Visual web frameworks such as Wicket or JSF usually have some components that facilitate pagination and most data access frameworks such as JDBC, Hibernate or JPA have facilities to access results in a paginated manner. Typically however, you need to write your own code to bridge the gap between the view and the data access mechanism. If you write your own glue code you will probably need to re-write it again and again if you want to re-use the back end code with a different view layer or change the data access mechanism.
Applications With DataValve
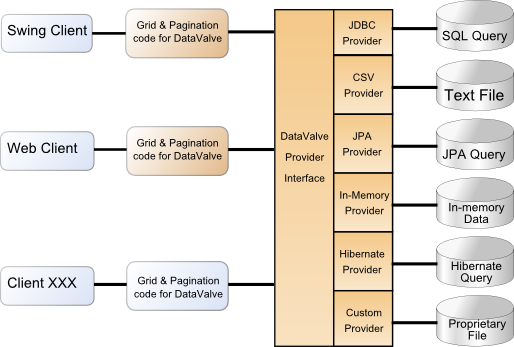
Exotic Data Sources
There may even be times when you have a sudden request to provide paginated data access to more exotic data sources such as XML, CSV, and binary files, even pulling data from a web service. In such a scenario not only do you have to write most of the pagination yourself, but again, your view layer will need some work to handle the new data access mechanism. This also includes paginated access to in-memory data that is regularly used, but changes rarely and is cached in memory.
Most of you are probably thinking that this isn’t a big problem because you write layered code with an interface that can have different implementations. You are right, logical organization of code can help with all these problems, however, at the end of the day, you still have to write something that integrates with the new datasource in the same way as the old datasource in the implementation.
If you are thinking that you will never need to change your view layer or data providers, there are still some problems you might want to consider that DataValve can help with.
Dynamic Querying
One common feature in data driven applications is to query a set of data using parameters with the ability to exclude query clauses where the parameter is not set. If you are searching for people, why filter by address if the user didn’t enter an address? The solutions to get around this problem involve either building the query at run time and ignoring restrictions with missing parameter values or accommodating the potentially null parameter in the query itself which makes it look ugly and can harm performance.
Ordering data safely
Another problem is the abstraction of the ordering of data, especially with web applications. You don’t want to store the actual SQL columns used for sorting data on the web page in case of SQL injection attacks. The best way is to use a key that maps to how you want the data ordered . You would also have to allow for ascending and descending ordering.
Parameterizing queries
Dynamic queries should be parameterized to allow variables in the query to be set in a safe manner as opposed to changing the query text which can again lead to SQL injection attacks. Typically though most parameters have to be set manually and many times we add new parameters and forget to set them. The process of adding and assigning parameters can require lengthy boilerplate code. DataValve offers vastly improved parameter handling for queries.
How DataValve solves all these problems
DataValve works by using a well defined interface to access and paginate data that comes from a data provider. There are different data providers for each kind of data source (JDBC,ORM,Hibernate,File based) and you can even write your own using an interface with just 2 methods. Because we have a well defined interface to the data, we can create components for the view to connect to that interface. Since we are coupled to the interface only, we can change the implementation and as long as it returns the same kind of entity objects, our view code remains unchanged. The view doesn’t care whether the list of Person entities comes from a database, an XML file, a web service or an in-memory list. When the dataset is connected up to a different view layer, it is coupled to the same interface and accesses the data in the same defined way.
Here’s a quick example of how we create a data provider and paginate the results.
DataProvider<Person> provider = new SomeDataProvider<Person>();
Paginator paginator = new DefaultPaginator();
paginator.setMaxRows(10);
pagiantor.setFirstResult(15);
List<Person> results = provider.fetchResults(paginator);
for (Person p : results) {
//do something with the 10 Person objects from 15-25
}
We can also use a Dataset that is a stateful combination of a Paginator and a data provider reference.
DataProvider<Person> provider = new SomeDataProvider<Person>();
ObjectDataset<Person> dataset = new DataProviderDataset(provider);
dataset.setMaxRows(10);
dataset.setFirstResult(35);
List<Person> results = dataset.getResults();
for (Person p : results) {
...some code...
}
Each time we call getResults() on the dataset, it will return the same list of results until we move to another page of results or manually invalidate the result set. Every time you call fetchResults on a data provider the list of results is re-fetched each time. The Dataset also implements the iterator interface so you could iterate over the whole set of data and it would go through each row, but load them in batches as sized by the paginator.
Queried Results
Let’s load a result set that uses some filtering and sorting.
QueryProvider<Person> provider = new JpaDataProvider<Person>(em);
QueryDataset<Person> dataset = new QueryDataset<Person>(provider);
provider.setSelectStatement("select p from Person p");
provider.setCountStatement("select count(p) from Person p");
//we can also access the provider using
// dataset.getProvider()
//add simple restriction
provider.addRestriction("p.department.id = 4");
List<Person> results = dataset.getResultList();
for (Person p : results) {
System.out.println(p.getName());
}
Alternatively, we could specify the parameters using :
//:param is a magic value for this method call only
provider.addRestriction("p.firstName = :param",someFirstName);
//alternatively
provider.addRestriction("p.firstName = :aFirstName");
provider.addParameter("aFirstName",someFirstName);
A few things to note here. The second method of using a parameter requires two method calls, but you can change the parameter value later on prior to execution and if aFirstName is null, then the restriction won’t be included in the executed final query. Typically, restrictions are excluded at the time of query execution, but if you use the first syntax, the restriction is left out immediately if the value is null since you are setting the parameter as a constant and if the value is null, then it will always be null.
Here are some alternative ways of defining parameters, all of which are subject to the rule that if the parameter is null, then the restriction isn’t added. All these examples can be used with either Hibernate, JPA or JDBC data providers with the only changes being the query specification and the field names in the restrictions.
//WRONG - if first name is null, then the param value is 'null%' and will be added
provider.addRestriction("p.firstName like :param",criteria.firstName+"%");
//CORRECT - this checks one value, but assigns another to the actual parameter
provider.addRestriction("p.firstName like :param",criteria.firstName,criteria.firstName+"%");
This is really useful where we want to use one value for the null check, but assign another value to the actual parameter so we can use ‘starts-with’ in searches by adding a wildcard on the end.
provider.addRestriction("p.department.id = 4");
provider.addRestriction("or p.managerFlag = 1");
All restrictions are joined together with “AND”s unless they actually start with a logical operator. Parenthesis can be introduced into the query, but care must be taken that opening or closing parentheses would not be removed in the event of a null parameter.
If you are using JSF or some other EL enabled environment, you can also use EL expressions directly in the queries as long as you attach an ELParameterResolver to the provider.
provider.addRestriction("p.firstName = #{criteria.firstName}");
provider.addRestriction("p.lastName = #{criteria.lastName}");
Again, if these expressions evaluate to null then the restriction is not used. This makes it really easy to create a search criteria bean that hooks up to the JSF front end and back end without any additional glue code.
Parameter Resolvers
DataValve has a concept of parameter resolvers that can be used on any data provider that implements the ParameterizedDataset interface. Parameter resolvers are like plugins that provide parameter resolution through code. The ReflectionParameterResolver uses reflection to find parameter values where the property name is the same as the parameter name.
provider.addRestriction("p.firstName like :firstName");
provider.addRestriction("p.lastName like :lastName");
provider.addParameterResolver(new ReflectionParameterResolver(criteria));
Our criteria object has first and last name properties that are used to resolve the parameter values in the restrictions. Again, if the values resolve to null, the restriction is not used when the query is executed.
Also, multiple parameter resolvers can be attached to a provider so you could use an EL parameter resolver and a reflection parameter resolver. This can be useful for mixing it up if you have multiple sources for parameters. You can also combine different combinations of adding restrictions.
provider.addRestriction("p.firstName like :firstName");
provider.addRestriction("p.lastName like :lastName");
provider.addRestriction("p.salesRep.id = #{currentUser.id}");
provider.addRestriction("p.dept.id = ",selectedDepartment.getId());
provider.addParameterResolver(new ReflectionParameterResolver(criteria));
provider.addParameterResolver(new ElParameterResolver());
Ordering Results
Configuring the order is simple, we add the order key values and associate information with each key to indicates how the ordering is executed which in most cases, it is the list of fields we use to order.
provider.getOrderKeyMap().put("name","p.lastName,p.firstName");
provider.getOrderKeyMap().put("age","p.dateOfBirth");
provider.getOrderKeyMap().put("id","p.id");
To order data when we fetch it from the provider, we need to assign a key order value on the paginator used to fetch the data from the provider.
Paginator paginator = new DefaultPaginator();
paginator.setOrderKey("name"); //order by the persons name
paginator.setOrderAscending(false);
List<Person> orderedList = provider.fetchResults(paginator);
If you are using a dataset, you can just set the orderKey and orderAscending properties on the dataset instead. These key values can be embedded in your web page and passed back to the server side components without having to worry about SQL injection. If the order key is not recognized as one of the available values in the order key map then no order is used and no SQL is injected.
State management
Paginators and data providers are separate instances while object datasets are made up of a paginator with a data provider reference that keeps a hold of the most recent set of results. The reason for this is so you can modify the degree of statelessness used.
You can make the whole thing stateless with the paginator info being passed between the client and the server. With Wicket, Seam, CDI and Spring Web Flow you might want to keep the paginator state on the server side but keep refreshing the results each time you postback. This can be done by keeping it in a Conversation, a Spring web flow, or a Wicket page. If you want to go fully stateful, you can use the Dataset which includes the paginator and the data provider and caches the recent resultset and put it in a Wicket page, a conversation or a page flow. By default, the JSF Components for paginating a DataValve result set is stateless.
Client Side
Briefly, lets look at the options for creating clients for DataValve datasets. There are components for a simple JSF paginator and a sortable column header for JSF 2.0 in the datavalve-faces module, and a SortableDataProvider for Wicket. For Swing, there is a special TableModel that caches and pre-emptively loads data for display in a Swing JTable. This means you can easily navigate thousands of rows of data in a Swing Table without having a long initial load time or taking up a lot of memory for object storage.
In the DataValve download there are demos for each of these examples in projects that are easy to run using the Jetty plugin for Maven so no server is required. The Wicket demo even demonstrates how different pieces of server side code can be reused with JDBC, CSV and Hibernate driven data providers.
Get Started
In addition to the DataValve project page you can see the documentation in HTML, Single HTML, or PDF. The download includes source that can be built and installed with maven as well as pre-built binaries.